KernelPwn之栈溢出利用
[TOC]
内核提权方式
内核提权有三种方式。
1.调用prepare_kernel_cred&&commit_creds提权
1 | struct cred *prepare_kernel_cred(struct task_struct *daemon); |
其中prepare_kernel_cred函数的作用是向内核申请凭证,commit_creds则是设置指定凭证为当前进程的用户凭证。
prepare_kernel_cred函数的参数为NULL时就会申请root权限的凭证。
所以我们只要让内核调用commit_creds(prepare_kernel_cred(0))即可实现提权。
2.修改task_struct->cred结构体下的uid等标识符实现提权。
task_struct结构体部分内容如下
1 | struct task_struct { |
其中cred成员指向着用户凭证,comm为程序名称。
cred结构体部分内容如下
1 | struct cred{ |
在有无限任意地址读写的情况下,我们可以通过设置程序名称为特殊值,然后去搜索内核堆空间找到task_struct结构体的位置,然后泄露cred地址,最终修改cred提权。
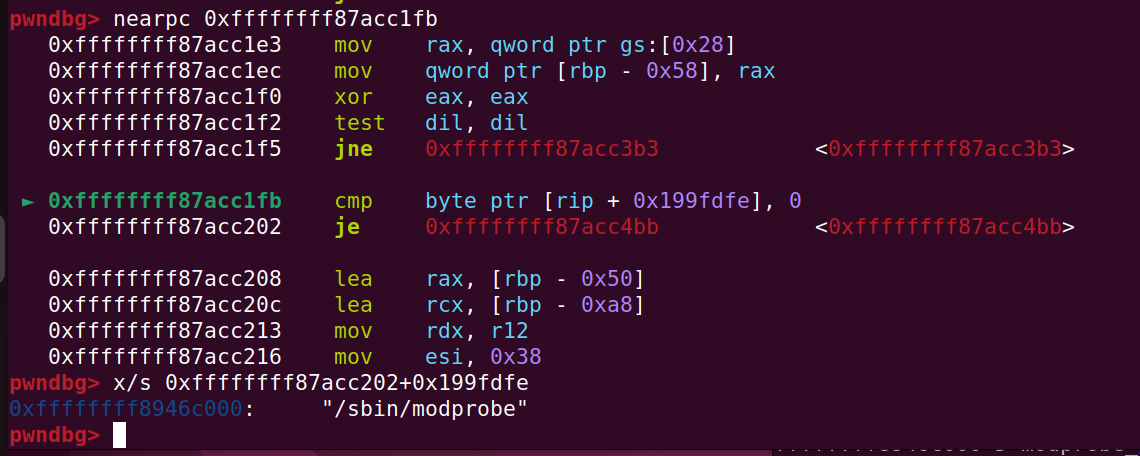
3.劫持modprobe_path提权。
当我们在执行一个非法文件时,系统会以root权限去执行modprobe_path所指向的文件,而modprobe_path存放在内核的可写空间中,所以我们只需要修改modprobe_path即可提权。
查找modprobe_path有两种方法
执行cat /proc/kallsyms | grep modprobe_path得到其地址
通过gdb调试跟踪函数__request_module,找到其取出modprobe_path的位置,得到其地址。
无保护
无任何保护情况下的栈溢出利用起来十分简单,我们可以直接在用户空间存放代码,然后修改返回地址跳到用户空间执行代码(ret2user)。
在用户空间布置代码,然后内核直接跳到用户空间的privilege_improve函数执行commit_creds(prepare_kernel_cred(0))进行提权。
1 | void getshell(){ |
smep机制
smep(Supervisor Mode Execution Protection)机制,禁止内核态执行用户空间的代码,所以我们
的ret2user方法失效了,此时有三种方式可以绕过。
1.rop
虽然进入内核态后,不能执行用户空间的代码,但仍能访问用户空间的数据,所以我们可以mmap一块内存布置rop链,然后栈迁移到该地址,最终rop提权,具体手段和普通pwn一样,就不多概述。
2.ret2dir
内核在设计时为了提高内存操作效率,在用户空间映射内存的时候,内核也相应地在内核的低端内存区地址映射一段影子内存(即复制了一份用户空间到内核空间)。
所以我们可以通过mmap大量的可执行内存,映射到内核区域,然后通过地址猜测跳到映射区域执行代码。mmap喷射的内存越多,成功率越高。
3.调用native_write_cr4
内核的smep保护是否开启由cr4寄存器的第20bit判断,置1则开启。
我们可以通过调用native_write_cr4修改cr4的第20bit为0,关闭smep从而执行用户代码。
不过后期内核版本加了校验,cr4的第20bit在启动后无法修改,所以此手段失效。
smap机制
smap(Supervisor Mode Access Protection)机制,禁止内核态读取用户空间的内容,所以在用户空间布置rop链失效,以下有两种绕过手法。
1.布置rop链在内核空间
利用漏洞驱动自带的函数或者内核的一些函数,往内核空间写入rop链,如内核的msgsnd函数会调用load_msg函数创建堆块存放用户发送的数据。
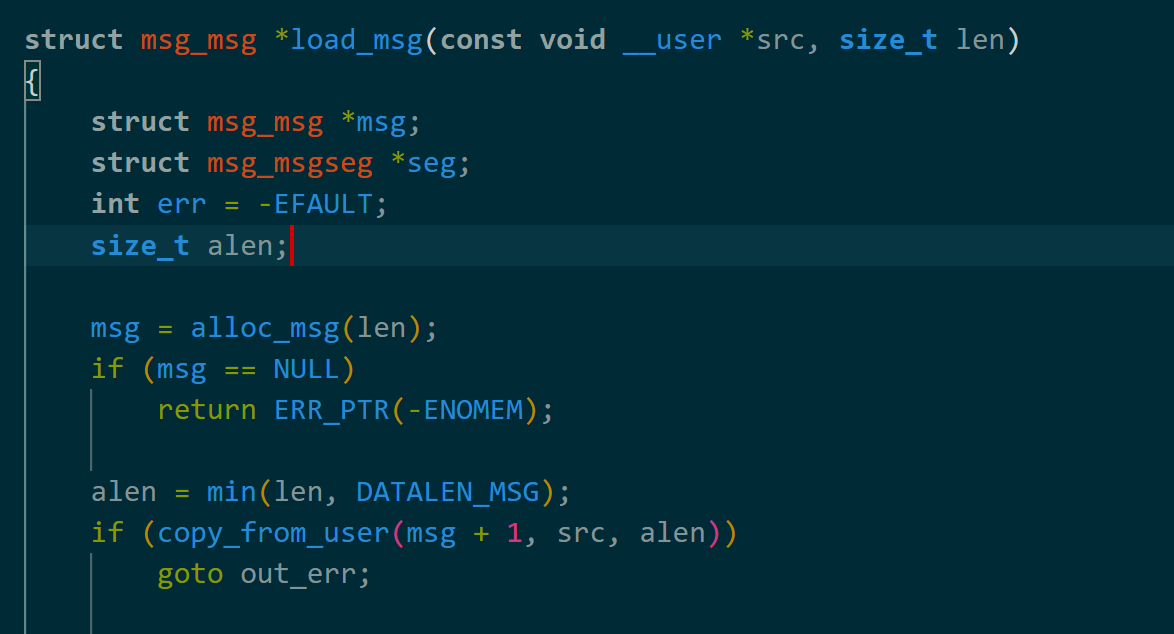
不过利用的前提是泄露堆地址,当然也可以通过大量喷射的方式,猜测栈迁移到该地址进行rop。
2.rop2dir
和先前的ret2dir一样,通过喷射的方式将rop链喷射到内核空间,然后通过猜测的方式栈迁移到该地址进行rop。
以上两种方式都提到了喷射手法,但喷射手法要注意布置rop链,为了保证其能完整跳到rop链的开头处,我们需要在rop前面存放大量的ret地址,构造滑梯将其滑到rop链开头执行。
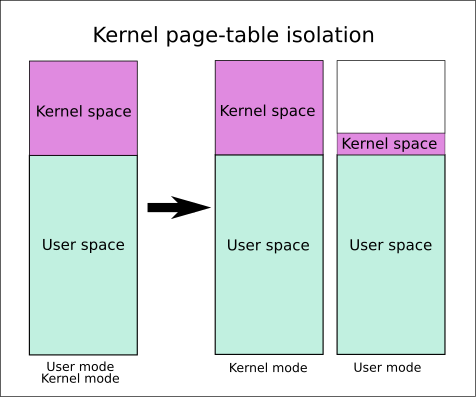
kpti机制
KPTI(Kernel Page Table Isolation)机制是一种安全机制,用于隔离用户空间和内核空间的页表。
当KPTI机制被激活时,内核会将用户空间和内核空间的页表完全隔离,而不是仅使用一组同时包含用户空间和内核空间地址的页表,可以有效减少侧信道攻击造成的敏感信息泄露的可能性。
开启kpti后,相当于同时开启了smep和smap,并且映射区域也被设置为不可执行,所以ret2dir也失效了,不过可读取数据,rop2dir仍然可以利用。
需要注意的是,开启kpti后,由于页表隔离,所以直接切换回用户态执行代码会报SIGSEGV错,可以使用以下两种方式绕过。
1.signal_handler
用户态设置signal_handler处理SIGSEGV信号,当触发SIGSEGV时就会调用到我们的signal_handler函数,我们将signal_handler函数直接设置成getshell函数即可。
1 | void get_shell() { |
2.swapgs_restore_regs_and_return_to_usermode
KPTI保护切换页表是通过控制寄存器CR3来控制的。
当CR3第13bit置1,就可从内核态页表切换到用户态页表。
而swapgs_restore_regs_and_return_to_usermode即可修改cr3,实现页表切换。
1 | arch/x86/entry/entry_64.S |
我们只需要跳到mov_rsi_rsp处,布置栈空间如下:
1 | rsp ----> mov_rdi_rsp |
便可返回用户空间执行代码。
kaslr机制
kaslr其实就是内核版的aslr,机制和程序的基本上一样,基地址随机,但是偏移不变,所以我们只要泄露了内核地址就可以通过偏移得到内核基地址从而利用。
fgkaslr机制
为了补充kaslr机制的短板,又重新引入了fgkaslr机制,其在kaslr机制的基础上又增加了更细粒度的内核地址空间随机化,按照函数级别的细粒度来重排内核代码,从而增加了攻击者利用内核漏洞进行攻击的难度。
这种机制通过随机化内核函数的位置,使得攻击者难以通过传统的手段(如泄露内核地址并通过偏移计算内核基址)来定位关键函数,从而提高了内核的安全性和稳定性。
它会选择性的重排一些段,以下是关键代码。
1 |
|
由此可知,符号节区不进行细化(细粒度的地址随机化),只有同时有SHF_ALLOC与SHF_EXECINSTR标志位,并且节区的前缀为.text才会被选择进行细化,并且第一个.text段不会进行细化。
可通过命令readelf -W -S ./vmlinux | grep -vE 'AX'查找不细化的段(还有第一个.text 段)。
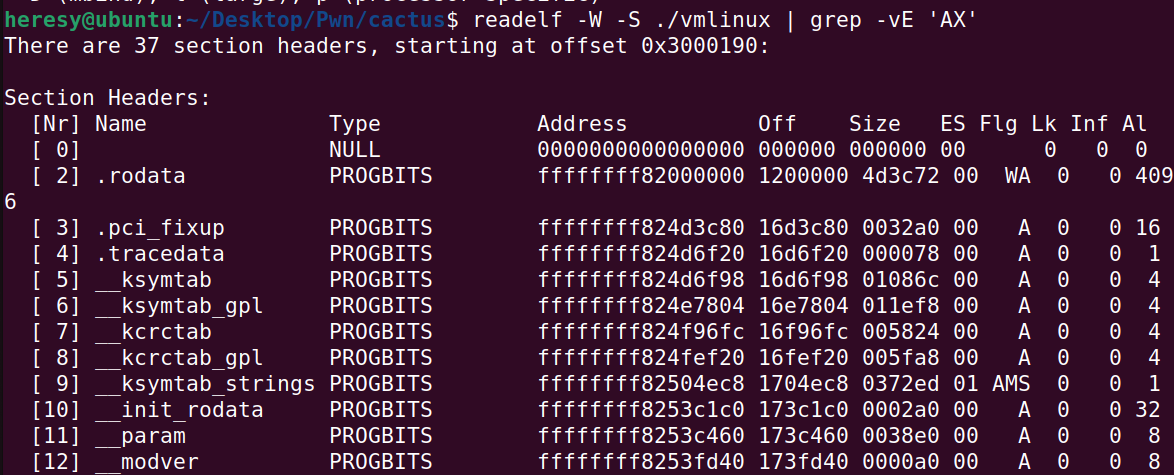
利用手法也很明显,就是泄露不细化的地址得到基地址,然后利用未细化的地址存放gadget实现rop,或者泄露细化的地址,利用该段内的gadget实现rop。
- Title: KernelPwn之栈溢出利用
- Author: 0rb1t
- Created at : 2024-08-05 21:42:17
- Updated at : 2024-08-09 15:55:54
- Link: https://redefine.ohevan.com/2024/08/05/KernelPwn之栈溢出利用/
- License: This work is licensed under CC BY-NC-SA 4.0.